Text Analytics: 10 Hospital Webpages
Introduction
This analysis was completed as a final project deliverable for my Masters of Science in Applied Data Analytics at Boston University's Metropolitan College. The course was the third of 9, Web Analytics (using R).
This project will analyze the webpages of 10 different hospitals, looking at both word choice and word frequency on their home pages. Some of these hospitals are top-ranked in the country, some are local to Boston, and some are nationally recognized hospitals for cancer treatment.
This is a summary of the project, and you can review the code here.
STEP ONE: Identify the webpages
These are the ten hospital pages analyzed in this project:
| Webpage | URL | Group |
|---|---|---|
| Mayo Clinic | https://www.mayoclinic.org | Top 4 |
| MassGeneral Hospital | https://www.massgeneral.org | Top 4 / Boston |
| Cleveland Clinic | http://my.clevelandclinic.org | Top 4 |
| Johns Hopkins Medicine | http://www.hopkinsmedicine.org | Top 4 |
| Brigham and Womens | https://www.brighamandwomens.org | Boston |
| Boston Childrens Hospital | http://www.childrenshospital.org | Boston |
| Boston Medical Center | https://www.bmc.org | Boston |
| Dana Farber | http://www.dana-farber.org | Cancer |
| Sloan Kettering | http://www.mskcc.org | Cancer |
| MD Anderson | http://www.mdanderson.org | Cancer |
STEP TWO: Access the webpage text
When the raw html comes in from the web scraping pull, it's fairly indecipherable:
I then use the Selector Gadget Chrome extension to separate out the tags. This is a bit more readable, but still has a ways to go.

Finally, I strip out all the html tags and remove extra characters, whitespace, and lines that are exact duplicates. This is something I can work with!

Now we can run this same processing for all the hospitals on the list and then combine the 10 files into one corpus.
Step Three: Clean the text
When we first use the document term matrix to see which words are most represented on these sites, we immediately see a problem. The top words are very common words and don't add much to the analysis. 70% of the top 10 words fall into this category.

To address this, I did some text preprocessing. I transformed all text to lowercase and removed numbers, stopwords (common words), and punctuation. I then recreated the document term matrix and we see that the words carry much more meaning.


Now we're ready to take it a step further.
STEP FOUR: Analyze the similarities
To compare the content of the hospital pages, I created a dendrogram. The two things we look for in the dendrogram are clustering and color. Both will tell us how (dis)similar the pages are from each other.
Let's take a look at why this might be.
Top-ranked hospitals
Mayo Clinic, Mass General, Cleveland Clinic, and Johns Hopkins are the top 4 hospitals in the country, according to US News & World Report (as of 2019). I expected that they would either cluster together or at least appear to be on relatively equal footing (distance-wise), but their webpages are fairly dissimilar. The main reason why Mayo Clinic stands so far apart from the other three is in its word frequency - its top five words all appear more than 30 times on their home page and none of the other hospitals have any words appearing more than 20 times.

Cancer hospitals
Two of the cancer hospitals (Dana Farber and MD Anderson) are clustered separately from the rest of the hospitals. This makes sense as their content is likely different and more targeted than the others. Sloan Kettering is also a cancer-specific hospital, but it is clustered far from the other cancer hospitals.
When we look at the words on each of the cancer hospital pages, we can see why Sloan Kettering is clustered so differently - Dana Farber and MD Anderson have much higher word frequency in general, though Sloan Kettering's actual top words are similar.
Cluster-wise, Dana Farber and MD Anderson are less similar to each other than are the purple hospitals. With three cluster colors, Dana Farber and MD Anderson are the same color and cluster. When I added a fourth color, I expected the purple hospitals to split, but it turns out the the Dana Farber and MD Anderson pages are less similar to each other than all the purple pages.

Boston hospitals
Mass General and Boston Medical Center form a sub cluster nested under Brigham and Women's and Boston Children's. Some of this clustering may be due to their proximity (and similar wording with locations), but Children's and Brigham and Women's also do have higher word frequency of their top words.

STEP FIVE: Analyze the top words

This wordcloud represents the 75 most frequent words across all 10 hospital websites. Unsurprisingly, the words are patient- and research-focused.
Step Six: Why is this important?
When we visit a website, we can take in the imagery, the tone, and the context. We can get a impression of a site and construct an subjective opinion of the hospital based on their virtual first impression.
By using text analytics, we can start to apply an objective measure of the language used on the site. We can evaluate how the hospitals are positioning themselves and what the topics are that they feel are most important in their first impression. By comparing one page to another, we might be able to tease apart where there's a gap: is there a specific topic important to your hospital that isn't on another hospital's webpage? Perhaps by putting that on your webpage, you'll capture visitors' interest faster than another site which has that topic buried deeper into the site.
Text analytics does not provide a directive (“we should be like hospital A” or “we shouldn't be like hospital A”), it provides information. And information is power. Knowing what the competition is doing can help to determine strategy moving forward.
And finally, a caveat. Webpages are constantly changing. If you run these same webpages today, I guarantee you that you will pull a different dendrogram and a different wordcloud. This is one of the reasons why they shouldn't be used as gospel for determining strategy, but they can provide information while defining that strategy.
post-covid update
Updated July 2021
My expectation going into this update is that I would run the code and find fairly significant differences to the pre-COVID data above.


On the whole, we see that the differences are not large. Dana Farber and MD Anderson are still off on their separate branch, and Mayo Clinic still stands separate from the purple grouping.
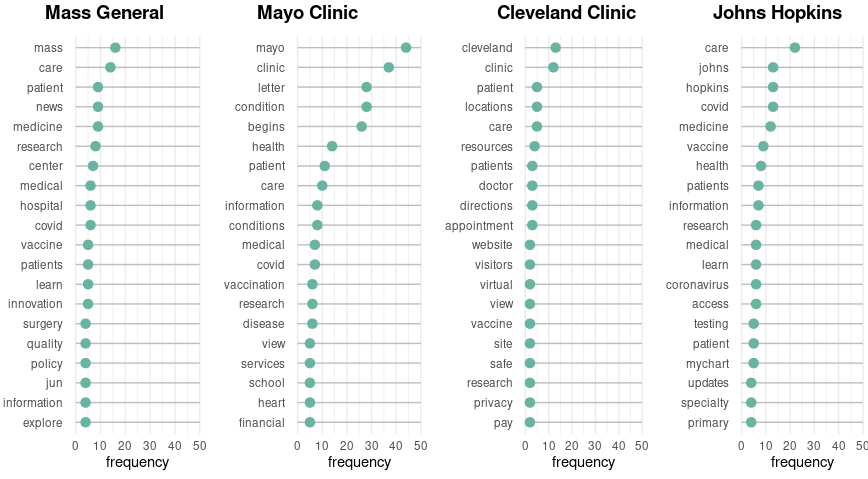
What is interesting in the 2021 update is how the purple group has shaken out. Some are the same, like Cleveland Clinic and Sloan Kettering sharing a parent node. The biggest difference I see here is the coming together of Johns Hopkins and Mass General onto the same parent node. A likely reason for this is the high profile both hospitals had during the pandemic. Johns Hopkins was the center of many pandemic statistical updates (for instance, the Boston Globe referred to Johns Hopkins data in their daily Coronavirus updates newsletter). Mass General also helped to spearhead the COVID response and Mass General's head of infectious disease, Rochelle Walensky, was later nominated as head of the CDC.
Looking at the comparison of the most common words for the top-ranked hospitals, we can see that this is likely the case. Mayo Clinic is still separated from the others by the vast difference in word frequency. Comparing Mass General to Cleveland Clinic and Johns Hopkins, we see that Covid-related words (covid, vaccine, innovation, coronavirus) appear on the top lists for Mass General and Johns Hopkins much more often than on Cleveland Clinic's page.
Top terms used on hospital home page: 2019

Top terms used on hospital home page: 2021