Predicting the Weather in Boston, Seattle, and Los Angeles
Introduction
This was my final project for my graduate course Data Science with Python, which I took towards completion of my Masters of Science in Applied Data Analytics. This page includes the report and graphical results. To also view the Python code used in this project, please visit my co-lab page.
OBJECTIVE
Using data from the National Oceanic and Atmospheric Administration (NOAA), this analysis considers the creation and assessment of models that predict the weather based upon temperature and seasonal conditions. While we primarily want to look for accuracy in our prediction model, the number of false negatives is also of higher importance than the other quadrants of the confusion matrix (particularly in Boston and Seattle). This is because we don’t want to predict a dry day, leave our umbrella at home, and get wet. Los Angeles also needs to take into account false positives to a higher degree than the other cities; because they get so little rain over the course of the year, knowing when it will rain may be more important for agriculture.
PREPARING THE DATA
PULLING THE DATA
I downloaded the data directly from the NOAA website for the purposes of this analysis. I have in the past also directly downloaded the data using Requests, but I'm not including that code here. The weather stations I used were:
- USW00014739 for Boston (Logan Airport)
- USW00024233 for Seattle (SeaTac Airport)
- USW00023174 for Los Angeles (LAX)
Data from each city (Boston, Seattle, and Los Angeles) includes the following fields:
- Station ID number
- Station location
- Date (reported by day)
- Average temperature
- Maximum temperature
- Minimum temperature
The data also include boolean fields that indicate if the day included the following weather:
- Fog
- Heavy fog
- Thunder
- Sleet
- Hail
- Rime
- Dust, smoke, or ash
- Dust
- Blowing snow
- Tornado
- High wind
- Mist
- Drizzle
- Freezing drizzle
- Rain
- Freezing rain
- Snow
- Unknown precipitation
- Ground fog
- Ice fog
For the purposes of this report, we will look at rainy weather in the years 2000-2012. Rainy weather is counted as any day which has ‘drizzle’, ‘rain’, or ‘unknown precipitation’. Freezing rain (and anything similarly wintery) was not considered.
OVERVIEW
Boston, Seattle, and Los Angeles were chosen as they represent stereotypically different weather patterns (Boston is colder, Seattle is rainier, and Los Angeles is sunnier).
What we see is that while the max temperatures and average temperature range for the 13 year span are similar across cities, Boston is considerably colder in the winter. Unsurprisingly, we also see that Seattle has the highest chance of rain and Los Angeles the lowest. One of the things we will investigate is whether a city with more rain is also easier to predict rain for.

WRANGLING THE DATA
CREATING A PREDICTION METHOD: Monthday
We know from experience that certain times of year have more rain than others. April, for instance, is notorious for rainy weather (in Boston, at least). This method of prediction looks at the training set (2000-2008) and for each day of the year, calculates the percentage of time it actually rained on that date each year in the training period.
For that, we assessed the actual rain percentage vs. several pres-set thresholds (30%, 60%, 90%). If the actual rain percentage was higher than the threshold, we predicted rain for that day. The fourth prediction column was an ensemble measurement - if two of the other fields predicted rain, then the ensemble predicted rain (or vice versa).
Looking at all three cities, we will use the 30% threshold in our overall assessment. For more details on why 30% was chosen, please visit my co-lab page.
ASSESSING THE PREDICTION METHODS
Boston. Random Forest has the highest accuracy of all the models, but also the highest incidence of false negatives, which essentially disqualifies it. Because four of the models are so closely matched on accuracy (all but Monthday), TPR and TNR broke the tie. I consider Naïve Bayes to be the best model in this instance, as the accuracy is still high, while the false negatives are the lowest of the top models.


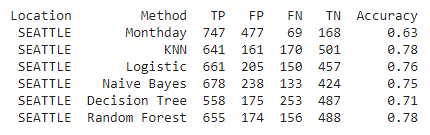
Seattle. Random Forest and KNN are the models with the best accuracy. What breaks the tie is the lower incidence of false negatives with Random Forest.

Los Angeles. The main contenders for best model here are Random Forest and Naïve Bayes. KNN has a high accuracy, but also high false negatives. Naïve Bayes has the lowest false negatives, but also high false positives. With that and the higher accuracy, Random Forest comes out on top.


CONCLUSION
With the data modeling methods used here, it seems easier to predict rain in either an arid climate like Los Angeles or a wet climate like Seattle. Boston, with its high variance of weather and temperature, is much more difficult to predict. We can see this highlighted in the confusion matrices above.
- Boston: we predicted the weather correctly only 63% of the time, getting unexpectedly wet nearly a quarter (24%) of the time, and staring at the sky expecting rain 13% of the time.
- Seattle: we predicted the weather correctly 78% of the time, only getting unexpectedly wet 11% of the time, and only staring at the sky expecting rain 12% of the time.
- Los Angeles: we predicted the weather correctly 87% of the time, only getting unexpectedly wet 10% of the time, and only staring at the sky expecting rain 3% of the time.
To sum everything up, your best bet is to watch the news to predict the weather. Barring that, the best prediction models from those tested here are Naïve Bayes for Boston and Random Forest for Seattle and Los Angeles. Or just always carry your umbrella with you.